

|
|
|
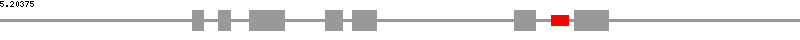
| Caenorhabditis_elegans F55A11.6 | ||
| organism | Caenorhabditis_elegans | |
| locus name | F55A11.6 | |
| chromosome ⁄ contig | V | |
| snoRNA list | F55A11.10 | |
| snoRNA position | 2869..2959 | |
| length | 4164 | |
| sequence |
TTTGAACATTTCATAACGCTCATTTTAATACCGAATGATTTATTTGAACGTTTTCAAAA
GCACTGCTTCAAAATGTATAGTTTTAAAATTAAATAAAGCGATTATATAATGTCTCAATG CAGCTGAAAATTTGTTCTCTTTTTTTCAACTTTGGGTTGTAGTTATGTTGTGATGATTCC AATTACCAACTGTGCCTAAGGTTTTCCAAAAATACCAACATTTTGGTGATGAACCAATAT TTAAAGAAAAAGTTTTAAAAACATTATATTGTCGTATCATTTCAGAAAAGAACAATTTTC AATATTCGAAAAACAAATGTTCAGACATCGAGACGAGATTTCTTGATATATGGTTGTTTC GTAAAACTTTAATGGCATTTAGGAATAAAATGTTCTCTTTTGCTACTGTTACCTTTTAAA AATCCATTTTCGAAAATAAACTAAATTATCAAAAAAATTTTCGATTATGAATCAAGAAAT CTCAATGGAGTTCTTACATTGGAATTCTTATTCAAATTTGTCCTGTATGACAGGAATAAA AATGGAAATGCTCTAATTTCCAAATTTCCTCACAATTAAATATTACATACCATTTTCGAA AGAATTCGTAAAGTTTGGTTTATTTCACATTTCTTCAACGAAAAAAAAATAGAAAAATAT ACAGGTTTTAAGATTTCAAAAATTGCCTATTTCTCCTAGAAATTAGTTCAATCTTAAAAA TAGTTTACCTAGAAACAAAACAGACAGAAAATTTGGAACTTGACGAATGTCAATTGCAAG TCTGCAGGTGTCGTGAAAAACACGAATGAGCTGCTTGATTTTTCTTGATCAGCCTTTCCC TTGACCATGCTCATAATAGCATTTGAAATCAAGAGACGCAGACAAAGATAAATGAGTTCC GTCTGTGATTTGCTTTCCCCCTCCAACAACTCATTCCTCACCCGATTTCTCCAAAAAACT TATTCTTATTGTAATAAAAGAAAACAGAATATATCAATAAAATGACTCCAAGCCTTGCTC TACAGTATTCTATTACTTATGCCCTTTCTCCAAAGTTCGTGGTTCGTGTTTTCTTCCTTT TTTCATAATTTAACTCATTGGACGTTTAAGTAGAAAATTGCAATTTTAATTTCAGAAATC ATCAAGCAGTGGCCGACATCTCAGTGTTTCTGTAAGCTCAACAACTCAGAAGAACTTTGT GAGTTTTTTTTTCAGAGGAAGGCTCTGCCTGACTGGAATTCTTTCACTTTTTAATCTAAA AAACGATAATAGTATTTAGAAATTCAATTTCAGTTTCAGCCAAGCCCTGTTCAAAGCCGA AAGAATAAAATGGACACAATGCACGGATTTCTAGTTCCAACCTACACTTTACATGATTTT GATGATGGGGAAGAATGTAAAGTTGTCAGAATGATATTCCAAATGTCTAGAGTTCCATAT GAGTTCAAGCATGTTCATCGAGATGATTACATTCTTGAAGGTATGTGTTTTTTTTTAATT TGCATGGTTTTTATATGTATTTTTCACCAAAGACTTTACGAAGCAACTACATTAGTGACT ACTGTATAGTGCAATAATGATTTTTAACGTTGCGTTTGGGAATAATAAAAGAGAATATAC GGTTCATATAACGAGAACAATATAGATCAAGATTTAAGTATTTCGAATAACAGCTAACAA ATGTTTTTCCAGATTACCCATTCTATGCTCTCCCAACACTTGAAATGAATGAAAGAAAGT ACGGAAGTGTTTTGTCAATTTGCAGACACTTGGCTTGGAGATACAGTAAGTTTTGAAAAT TTTCTGTTTTCATCGTATCTATTAGTTTTAAAGATTTGTCTGGAAAAACGGCATACGATG ATGCTCAAGTTGATGATATTGCAGAAAAAGTTTTTGAAGTTCGAATGAAAATTAAAAACT GGATTGATCATATTGAGCATGCGGCTGATCATGCATGTGATGTAAGTTGTTTTTTCTTTC TTTTTTTAAATTTTGATTCCCAGAAATTTGCAATTGTTGCGCTAAAAGTACGCTTCCTGG TCTCGCCACGACATGTTTTTCTCCAATTCAAAAAGCGCGCGCCTTTAAAGAATACTGTAA TTTCAAACTGCCGTTGCTTCGTAAATTCCAGCGATTTTATAGTTTTTTGATAAAAATATA TATTTATTCAAGATCTAAAATTTAACATTAAAAACAGATACATTTTCACAAATTGTATTG TGGAAAAAACTTCCAAAAAATATGAAAGTTCCGCAGCATGCTGCGCGCGCAGCAACGTGA GTTGGAAATTACAGTAATCTTTAAAGGCGCGCATCTTTTTGCATTTGAGAAAAATTTGTC GTGACGAGACCGCGGTCTAGACCGGGTACCGTTGTTTGGCCCAAAAATCTCAAAATTGTT GAGTCTAGGCGATGGGTTCAAATCCTGGTTGCTGAAACATGTACGCTTCTTCAAGAACTA CAGTGTCCATTCCTCGCAAGTTCCTTGAAATTAAAAAAAAAATTGCATAAAAATCTACTA TATAAGAACCAGAGAAAAAATGCCGAAAAAACAAGATTGAGGTTACTGTAGTTCTCACAG GTGCTCACCTTTTTCGCGTGAACGATTTAAAAAAGTTTAATTCTAACCAGAACTTACAAA ATAGTGTTTTCATATTTTTCAAATAAAAAAATATTACAGGAGGAATGTACAGAGGAAATT GCGCCTCGTATCCTTACCAATACACTGTTTCCTTGCCTCGAACGAATGTTGAAGTCGGCT GCCTCTTGTTGGCTAGTTGGACACACAGTGAGTGTTGCGCGCATGGCGCAGGCGGTTAGA TTGCTGAACTAGTGCCTCGCCGTCTGTTCCCGCTAGTTCGACACCTATCGAGCGGTGATG AATGCACGTATTGCTCTGACACCTCTTATGTTAGCGGTAAATTTCCGTGCCGCGATGAGT CCACTAGGATCTCTGAGCTCTTTTGAGCTTCACATTTTGAATTTTCAGATGACTTGGGTG GATCTTCTCGTTGCATGCCTTGTGAATCCGATCATATACCATCGTCCAAAGCTGCTCCAA GATTTTCCATTGCTGTATTTACATAATGAAAAAGTGGCCCATCATGATGACCTCGTAGGA TTTTTATATCACGTCAGAACACGTAAATTCCAAGACAAAAAGTAAACGTGACCGTGAACT TTGCCCAAATCTTTCTTTTTTTGTACTTGCATTAATTTTAAATCATTTTTTCAATCATCG AGCCGGTTGTATTTCTCGTTTCATTCATTCATTGCTAACTTTTGTGGACAATAAAGAGAT TAGAAAAATGAGCCTGTCAAAGAATCGCAAAAGTTTGGATTTGGACGATGAAAATGAATC ATCGGCACACTACTTGCGTTCACAATGGACAGTCTGTGTCAAGTCAGCCAAAATTCTGAA GAAAGTGACTGTGGTGATGAGAAGTGCAGAGAGAGTTGATCGAGTTTTTGGATCAGCATG GCTAAAGTCTGAAAAGTACATGACAAAGGTATATTTTTAGATTTATATTTTTAATATTAA AATTTCAATAAATAGGTGAATGCTACTGATATCAATGTGCCAAAAGGAGCTGTTTTGCAT CCACATTTTTATCATTTCAATCCACCAATCACTAATATCGGTGAGCTAATTTCATAAATT CTCCCGAAGTTAACTTTTTAAAATTTTTCCAGGAAAATACTCGGCTCAATTAATTGGACG TGCTCTTCGTAACCGTGGAATCGAGCCAGGAGTCATATTTTGTTCTCCTACTCTCCGTAC TCTTCAAACGGCTGCTGCAATCGCCAAATCGACTGGTGCCCGGATTCTCGTTGAGCCAGG ACTTTTGGAGCCAATGGAATGGTATCGTCGAGCTGGTGCAAAACAATTGCCAGATTTTTT CGATGAAGCGCTGGATTTCCCACAAGTTGATAAAACTTAGTAAGCTGCAAGATGTTATAT TAACCTCATGAAAAAATATTCAGCAAGCCAATCTTCTCGATGCACGAATTTACCAGCATG TTCGGAGCAAAAAGCCAGGAGCAGTGTATTCAACGTATCATGCTAGTTGTGAAAAAGTGC AGATTCGAATTATAATATTTTCTTGTAATTATGTAATTTCAGTATTTGTGTCATTTTCCG TGATACTCCTGCTCTAATTATCGGC
Untranslated Region
Coding Sequence snoRNA |
|
| exon position | 1001..1060, 1135..1197, 1299..1479, 1692..1784, 1833..1960, 2679..2786, 2988..3164 | |
| CDS position | 1001..1060, 1135..1197, 1299..1479, 1692..1784, 1833..1960, 2679..2786, 2988..3161 | |
| accession no | ||