

|
|
|
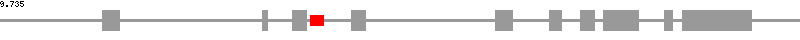
| Pan_troglodytes IF4A1_PANTR | ||
| organism | Pan_troglodytes | |
| locus name | IF4A1_PANTR | |
| chromosome ⁄ contig | 17 | |
| snoRNA list | SNORA48 | |
| snoRNA position | 3018..3152 | |
| length | 7789 | |
| sequence |
TGATTTCTGATGTGCAGGGGGTGGCTACAGAAAAGCCCCTTTCTTCCTCTGTTTGCAGG
GGAGTGTGGCCCTGTGGCCTGGGTGGAGCAGTCATCCTCCCCCTTCCCTGTGCAGGGAGC AGGAAATCAGTGCTGGGGGTGGTGGGCGGACAATAGGATCACTGCCTGCCAGATCTTCAA ACTTTTTTTTTTATATATATATATATATATAAATGCCACGGTCCTGCTCTGGTCAATAAA GGATCCTTTGTTGATACGTAAGTGGTGGTCTTCCTTAAGGGGCTTCAAATTAGTGGATAT GCTTAGCTCAGACCTTCCAGCCAGGCTCTTGAGACTAAAGGGTTCAGCTTTCCATCCCTG GCTCAGGCACTGCCAACACCTTGTCTTCACCCAAACAAGTCCCCCAGATGGGAGCAGAGA GCAGGAAGGAGGGAAAGTAGATAAGCCTCAAGAATAAGGGCATCCGAGAGGGAAGCTGGG GAACTGGACACAAGGGACTGGGGAGGGGACCAACCAGGATTCATGATAGTACCCCAAAGC CCTTTACAGTTTTCTTCCATCCCTCCACCATCCAGCCAGGGGAATCCTCCCATCCCTACG ATATCGCTGTTGATTCCTTCATCCCTGGCACACGTCCAGGCAGTGTCGAATCCATCTCTG CTACAGGGGAAAACAAGTAACAAATAATTTGAGTCCAGTGGAAACCTGGAGCAGAAGTAA AGGGAAGTGATAACCCCCAGAGCCCGGAAGCCTCTGGAGGCTGAGACCTCGCCCCCCTTG CGTGATAGGGCCTACGGAGCCACATGACCAAGGCACTGTCGCCTCCGCACGTGTGAGAGT GCAGGGCCCCAAGATGGCTGCCAGGCCTCGAGGCCTGACTCCTCTATGTCACTTCCGTAC CGGCGAGAAAGGCGGGCCCTCCAGCCAATGAGGCTGCGGGGCGGGCCTTCACCTTGATAG GCACTCGAGTTATCCAATGGTGCCTGCGGGCCGGAGCGACTAGGAACTAACGTCGTGCCG AGTTGCTGAGCGCCGGCAGGCGGGGCCGGGGCGGCCAAACCAATGCGATGGCCGGGGCGG AGTCGGGCGCTCTATAAGTTGTCGATAGGCGGGCACTCCGCCCTAGTTTCTAAGGATCAT GTCTGCGAGCCAGGATTCCCGGTAAGAAAGGCATTTGCAAGAGATTGTGGCTGCTTATTT TGCCGCCCCCTTCCGACGGGCCCGCCGGGGGTAGCTGAGAGGCCCACCAGGGTTGCGGGA GAAACCGAGCCGGGTGGGGGGAGGGTCCGACCTGGAGGGGCGAGGGGGAAGATCCACGGC CGACGCGGCCACCAGGTCGAGGCGGAGGGCAGGGACAGCCCGGCTAGGGTCAGGCGTGCG AGGTCTGTTACGAGGCCTCGACCCGAGGCGGTGCCATGCGCGAAGCCCCGGCGCTGAGTG GCGAGACGGGGTCGCGACCTGGCGTGGGAAAGAAAGGTGGAGGCGGCCGCCACTATGTGT GGCCCAGAGCCGGCAGGTCCGGTTGCCTCCCTGTGCCGGGGGAGGGACGGCGCGCGGGGT TCCGGAGCATTCTGACGGTACCACTCGCGAGAGGCGGGGGTGCTTGGTCCTTAGATCCAG TCACTTCGTCGCGGCTAAAGCACGGGTCGGGGAGAAGAAACCGGCCGTTCAGTGTGCTGG TTTTCTTGACGGCCAGGACTGAGCCTAACCCCGAGGAGCGGCCGCGTGAGGCACCAGGAG CCCACCCGGCGCCGGGCGGGCGGGTCCATTTTGCCGCACAAGCCGGGCTATTGGCAAACT GCGGATGGGCAGGTCCACCTTCCTTCGGGGGTGAGCGGCCTGAGGTATGGGAGGGCGACG CTACTTCGCGACGGGGGCGGGCGGGATGTGGATTGTTCCATGGAGGGTTGGGAGACGCCG CCGGGTGGTCGAGGGAGCGAGCACATGGTGGCCTGAGGCGTTCCCCTCCCCCAGTCTGCT TCGCTTCTAAGTGTTGTGCAATCTCCCCCTTTGCTAGCTCGGCTTGGGCTCATTGTGCGC GAGGCCGCCACCGCCCGCGGCCTCCCACATCCGGGCAACGCGAGGGGGGGCTTCGGCTGG AGGGAGTGGGGGAGGGCGCGGGCGGGATGACGTGGGGGGAAGGGGATGTCCTACCCTCCG ATCTGGGAGGTGAAGGGCGGGACTTCCAGCGCGCTGGTGCTGCGGTGGGAGGTGCACGCG CTTGGGCTTTAAGCGGCTGGGTCGGGCCCACGTGGACCCGGCGGCAAGCACCACCTCTGG GCACCGTGAGCGCGGCGGCACGCCTGCCAGCCTGTCTTCAGAAAGGGTCACCCCCTTATG TCGGGGGTGGCCTGGCCTGAGCCGCTGCCTGCATGGGGCAAATGCCTCAGTTTTATAGAA ACTCCTCCTTTGGGTACTTTTTGGGAGCTGGTGGGAGTTGGATCTGGGAGAGCAGGTTGA TGGCATCATGCAGGCCACTCCTGACAGAGCCCGGCTGTCAGGATTTCTGAGTGCTTCGGT CGGGCAGGGGACAAAACTTGTGCTTTAAACCAACAGATCCAGAGACAATGGCCCCGATGG GATGGAGCCCGAAGGCGTCATCGAGGTGAGACTGGAGAAATGGAATTCTGTCCTCCCCCA TTACAACTTTCAGCCTCACAGTTGTATAGAGTTAGAGTGGCCTCTTGATTGATTTCCCAG ACCATCTAGAAGCAGCTGGTTTCCCTAAAGGGAGGAGGGGTTGTAAGCTCTGAGGCTTTT GTTAGTGGGCACCAGATTCTGTTTGCTCTGAGACTACAGCTCAGCTCCACCTTTTCCATG ACTCAAGCTTTAATTTCTTTGCATCCCCTAGAGTAACTGGAATGAGATTGTTGACAGCTT TGATGACATGAACCTCTCGGAGTCCCTTCTCCGTGGTATCTACGCCTATGGTTTTGAGAA GCCCTCTGCCATCCAGCAGCGAGCCATTCTACCTTGTATCAAGGGTGAGACCTCTCAGTC CCAGAAGACATTGTGGACTGTCCCTGACCTGGGTAGAGTGGCATCTGGTTGGTGATGCCC ATCTCATATCAGCCAGGGACAAAGCAACTCCTTGTTCATCCCAGCTTGGCTTTTGATCCG TGCCCATGCCTGGTTCATGCCTTGGACACATAGTTTTCCTTTAAAGAGGTGGTATTGTAG CCAGCTTATACTTGCATCTACAGCCATGTTTCTAGTCCAGCTTGGTGTGCAATACTAGAT GAGTTAATAACTGGTCCTTGTTTCTGATCTGGTTCCCATTGTGTAACTGTTGATTGGGAA GGTAGTTTGTGAGCCATGAAATGCTTGGTTCATTGGTTGCTTATTGACCTCATTAACCTA GGACTTGAATATCCCAAAGGGTATGCTCTTTACCACATTCAACTCCTAATTTATTTGTTT AGGTTATGATGTGATTGCTCAAGCCCAATCTGGGACTGGGAAAACGGCCACATTTGCCAT ATCGATTCTGCAGCAGATTGAATTAGATCTAAAAGCCACCCAGGCCTTGGTCCTAGCACC CACTCGAGAATTGGCTCAGCAGGTAAGAGTGGCTTCTATTCCCTCCTTCAGGGCTGATTT AGGGATGATGAGTATAATCCAAGGACCAGAGAAGTCTTCTCTGATCACCACCTTGGGAGG AAGACATGGGTGCCCTAACACTCTCGAGACCTGCTGGGTTAATTAAAAGCTATTTCTTAC CCAAACGTAACCATTGCTTCCTCCACCCATTTCCTGAGTCAAATGGGAAGGCTGTTGGGT GAAGCCTGGCTGGCTGGGCAAGTTTGACTGTGTTCTGAATAAGCACCTTCACTATGGGCT AAGAGATACCTTGGTGGTGGGGGTGATCTTACAGTAGTCAGAGCAGATGGACAGTCCTTT TCACCCTTGCTAATGGCCAGAGCTGTTTCATGCCTGGGGCACACACAATTCTAATGCTGG ACTTTTTCCTGGGTCATGCTGCAACACTGATGTCAGAGCATGTTTTTAAATGTTCTGTGG CGGGGGCAGTGATTATTCTGGGTGTGGATAATGTAAGAAGTTACAGCAGAGCTCCATTCT AAGGCACTTGGCTCTCAGTTTTCTCAGAGTGAACATGCCTCGTAGTTTGGGTCCTATGGC AGGAGTGCAATAGGACATGGATATGCATCACCTGTTCTACAAAACTGGTTGCTGGCTGGG CGCAGTGGCTCACTCCTATAATCCCGACACTTTGGGAGGCCAAGGCAGGCAGATCACTTG AGATCAGGAGTTGGAGACCGGCCTGGCCAACATAGTGAAACCCCGCCTCTACTAAAAATA CAAAAATTAGCCAGGCATGGTGGCGTGTGCCTTTTATCCCAGCTACTCGGGAAGCTCAGG CAGGAGAATTTAACCCAGGAGGTGGAGGTTGCAGTGAGCTGAGATTGTGCCATTGCACTC CAGCCTGGGCAACGAGCAAAGCTCTGTCTCAAAAAAAGAAAAAAAAATGGTTGCTGCGTG ATGAGGCAGTTGGTCAAATTAGTTTTCAAAAGGTTAAGGGTTCTAAATATCTAGAGTAAG AAACTGAATTAATTATCTGAGCGGCCTCATTGTGAATCACTGTACACTCAGGAACCAGAC TGAGTTGAAATCCTGTCTTTGCCACCTATTGACAGCACGATCTTAAGTGGATTTTAGCCT CTGCCTGTTTCTCAGCTGAATGTGAGTTTAATAATAGTGCATGCCCCAAAGTTGTTGGTT AGGAATCAATACATGAAAAACATTTAAGAATGGTGCCGGGCACAGTGGTAGCTGACATAT GAGCACCTGCCTCTCTCTGCTCAGATACAGAAGGTGGTCATGGCATTAGGAGACTACATG GGCGCCTCCTGTCACGCCTGTATCGGGGGCACCAACGTGCGTGCTGAGGTGCAGAAACTG CAGATGGAAGCTCCCCACATCATCGTGGGTACCCCTGGCCGTGTGTTTGATATGCTTAAC CGGAGATACCTGTGTGAGTAATTCAGTTCTCCAATCCCCTGGGTCACTTTGCTCTTGTGC ACGCTTTCCAGTCTTTCAGCGTAAGCCAGAGTCATTCCCAAGGATGCTGGTTTCTCTCTG GGGGAAGAGCTGCTCTGTGATGGAGCCCATGCGTGTCATCTGAGCCTCTGGCTTCCCTGC CAGTGCAGCCCTGGCAGTGTCCTACTTCCCAGGGCTGTTGTCTGCCTGGCGGGAAGGTCC TGGGCAAAGGATCAGTCTTTGTACTCTGAGAGCAGACTACTTGGCCCCTCTGTGTTTTTT ATCAGCGAAGTTGGATATATCTCTCCCACATTTCCCTAATTATATGCTATATATTGGCTT TTTTTTTTCTCTAGCCCCCAAGTACATCAAGATGTTTGTACTGGATGAAGCTGACGAAAT GTTAAGCCGTGGATTCAAGGACCAGATCTATGACATATTCCAAAAGCTCAACAGCAACAC CCAGGTGAGGGCAGTCTTGCTTGAATAGCTAATGATTCTTGAAAAATAGTAAGTGCCAGG GGAACCAAATACTGGATTCTTGTCTTGAGCCTTTTTATGCATCTGCTTCAGTTTTAGGTG TGGCTAGGGAAGGGAGCAGGCCTCAGGAAGGAACCAGCACTCTAAGACTGGCCTTTTTTT CCACTAGGTAGTTTTGCTGTCAGCCACAATGCCTTCTGATGTGCTTGAGGTGACCAAGAA GTTCATGAGGGACCCCATTCGGATTCTTGTCAAGAAGGAAGAGTTGACCCTGGAGGGTAT CCGCCAGTTCTACATCAACGTGGAACGAGAGGTGGGGCCCAGTGCAGGAGGCGGGCCTGG TAGTGAGTTGTTGGGTATAGCCCCTGACTGATTTTTGTCCCCCAACCTCCAGGAGTGGAA GCTGGACACACTATGTGACTTGTATGAAACCCTGACCATCACCCAGGCAGTCATCTTCAT CAACACCCGGAGGAAGGTGGACTGGCTCACCGAGAAGATGCATGCTCGAGATTTCACTGT ATCCGCCATGGTGTGTTTGCCCGCTGCCAGCCTGTTGTGGGTCTGCCCGTCAGAAGTGTC CTACTTGAAGCCAGGGTTCCTGGAACCCATGTGCCTACCTGGTCTGCTGCATATTTGTTT TCTCTTCCAGCATGGAGATATGGACCAAAAGGAACGAGACGTGATCATGAGGGAGTTTCG TTCTGGCTCTAGCAGAGTTTTGATTACCACTGACCTGCTGGTGAGTTGAGGGAACTGATA GGAAAGGCAGAAGGGAGGATCCAAGGTGATTCCCTCTCCAAGGGGACATCAGTGCCTCTC AGGAAAGTAGCAGCTTGGAATAGAATCTGGCATGCCTAAGGCCTTTGGGGAACTGGGATG CTTATTTCCTCTGCCTTCCTTGGCTGCCCACATGGATGCCTAAGTGTCTTCCCTCCGGGA TAGAGTGTCCTCCGTGCACATGCTGAAGAGTTGTCTTTCTTGACGTAGGCCAGAGGCATT GATGTGCAGCAGGTTTCTTTAGTCATCAACTATGACCTTCCCACCAACAGGGAAAACTAT ATCCACAGGTAAGCGTAGATCTGGAACACTCCCCTACCCCTTCACACCTGGCCCTCCCTG GGCTTAAAGCTCCTGATATTCCTCATCCCCTTCCTTGTTTTCCAGAATCGGTCGAGGTGG ACGGTTCGGCCGTAAAGGTGTGGCTATTAACATGGTGACAGAAGAAGACAAGAGGACTCT TCGAGACATTGAGACCTTTTACAACACCTCCATTGAGGAAATGCCCCTCAATGTTGCTGA CCTCATCTGAGGGGCTGTCCTGCCACCCAGCCCCAGCCAGGGCTCAATCTCTGGGGGCTG AGGAGCAGCAGGAGGGGGGAGGGAAGGGAGCCAAGGGATGGACATCTTGTCATTTTTTTC TTTGAATAAATGTCACTTTTTGAGGCAAAAGAAGGAACCGTGAACATTTTAGACACCCTT TTCTTTGGGGTAGGCTCTTGCCCCAGGCGCCGGCTCTTCTCCCCCCCCCAAAAAAAAAAA AAAACACTAATCCATTTCCCTAACCTAGTAACCTCCAGATCCCAGAGGCTCTCCTCACCT CAGCTGAGCTCCTTTGAAAGTGATTCAAGGGACTATGTCACTCAGCCTCATTTGCTGGAC CAAATCTGGAGGGAGAACCCCTAAAACCCCTAAGTGAGGTTGCCCAGGGGGTTGTCCCCA GGTGGGGGGAAGCAGGGGAGAGAAAATGGTAGCCATTTTTACATTGTTTTGTATAGTATT TATTGATTCAGGAAACAAACACAAAATTCTGAATAAAATGACTTGGAAACTGCCTGTTTG GGCTTCTCATTTCTTACTTCCCCTTCCCTCTCCCACCTGCTACTGGATGCATCTCTGCTC CCCCCTTCCCCAGCAGATGGTTACCTTTGGGCTGTTGCTTTCTTGTCACCATCTGAGTTC CCAGACCCTGGAAAGCCATGTTCTCGGCTCTGAGAACGACAATGCTGACTGGAGTGCTGC CCCTCTGTAAAGGGCTGGGTGTGGATGGTCACAAGCCCCTCACGTGCCGCAGCCAAGAGG AAGTAGTACAGGGGTCAGCCCAGAGGTCCAGGGGAAAGGGGAGTGGAAACTGATTTCCCC ACCGAGGGAGGGGCCTGTACCTCAGCTGTTCCCATAGCCACTTGCCACAACTGCCAAGCA AGTTTCGCTGAGTTTGACACATGGATCCCTGTGGATCAACTGCCCTAGGACTCCCTGTTT GCACCCATGTGACACTGTTGACTTTGCCCTGATGAAGCAGGGCCAACAGT
Untranslated Region
Coding Sequence snoRNA |
|
| exon position | 1001..1160, 2556..2604, 2851..2983, 3422..3561, 4824..4992, 5354..5463, 5647..5790, 5872..6219, 6468..6547, 6645..7313 | |
| CDS position | 1138..1160, 2556..2604, 2851..2983, 3422..3561, 4824..4992, 5354..5463, 5647..5790, 5872..6219, 6468..6547, 6645..6789 | |
| accession no | NC_006484 | |