

|
|
|
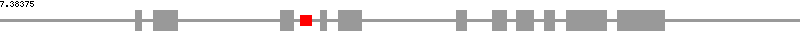
| Mus_musculus Ppan | ||
| organism | Mus_musculus | |
| locus name | Ppan | |
| chromosome ⁄ contig | 9 | |
| snoRNA list | SNORD105 | |
| snoRNA position | 2216..2298 | |
| length | 5908 | |
| sequence |
CATCTCCAGGCCTCATATGGCAAAAGGAAAGAACCAACTCTTTTTTTAAAGAGTTATTT
ATTATATGTAAGTACACTGTAACTGTCTTCAGAAACACCGGAAGAGGGCGTCAGAACTCA TTATGGTTGGGAGCCACCTTGGGGTTGCTGGGATTTGAGCTCAGGGCTTTCGGAAGAGCA GTCAGTGCTCTTAACCGTTGAACCATCTCTTCAGCCTGAGAACCAACTCTTAAAAATGAC CCTCTGATCTCCTCATATGCACCACCACAGATTGGCCTAGTCGGCCATCACTGGAAAGAG AGGCCCATTGGACACGCAAACTGTATATGCCCCAGTACAGGGGAACGCCAGGGCCAAAAA AAAAAAAAAAATGGGAATGGGTGGGTAGGGAAGTGGGGGGGAGGGTATGGGGGACTTTTG GGATAGCATTGGAAATGTAACTGAGGAAAATATGTAATAAAAAATATTTAAAAATAAATA AATAAATACAATCTATTTGGAGAGGGGGTGGACATGGTGGTACAAGTCTTTAGTTCCTGT CCTTGGAAGATACGGGCCCACGGATCTGTGTGAGTTTAGTCAGCCAGGAAGGGTGGCACA TGCCTCTAATCCCAGCGCTCAGTGTACGCACGCGGATCTCTGTTAGTTGCAGGCCAGCGT GGGCTGCGTGAGATCCTGTTTCAGAATAAAAAACTGAAAGGCCAAACAAAGGGGGCAGTA CGCTTGCCGAAACGTTCAGGATAGGGACTCGAACCCTCAAATAATTGTGAGGCCCCTCTC TTTTGTGCAAAAAGGACCACGGCATCTTTATAAAGACCCCTGGAAAGGATTCTCGGTCCT TTAAGCCGTCCGGAGCCAAGGACCGTTGGATGACGTCACTGGCCGGCACGCAGGAAGTGG GAAGAGTTACGAGCCGCGTGGCACCGGAAGTTGGCCACGTAAAGTCCGTCCTCTTTGCGT CTCCTGCACGGAAGTGAGCGGTGTGCGCCGGAAGCGAATACAGAGGCTGCCTCGTGGGGA AGCAGGCAGCATGGGGCAGTCCGGGCGGGTGAGGCGCGGCGGCCTGGGCGGGCATGGGGC ACTGGTGGGGTCGCGGCCGAAGCTTGGGCGCTCACCGCCTGCCTGTCGTCCCCGCAGTCC CGACATCAGAAGCGCAATCGCGCCCAGGCGCAGCTCCGCAACCTCGAGTCCTACGCTGCA CAGCCGCACTCGTTCGTGTTCACGCGAGGCCGAGCGGGTCGCAATGTCCGGCAGCTCAGC CTGGATGTGCGGCGGGTCATGGAACCTCTCACCGCTACCCGCCTGCAGGTCTGTATCCCT CAGCCCTTCAGCTCCAGGTTCGGGGCTCGGCATCTTGGCGAGGACTTGGGGCCAGAAGCT GAGCGCCTGCCTTCCATGTGGGAGGGCTTGGCTGAATCCCCAGCACCTCTGACCCAGGCT TAATGGTGTGCAGGCGAAATCGGGAATAGAATCGAGGGGGAAGATCACCATAGAGACCAT CTGTGGTTACATAGTGAGGTCTTGTGTAAAAAACGGAAAGTCATACTTTGGGGGCAATCG CTAGGTGACTCAGTGGGAAAGGGGGCTTGCTGTTAAACTGTAGTTCAATTCCTGTGCCCC ACGTAGTGGAGGGGGTGAAACAGCTCCTGAAGTCCTCTGACCTCCATCTTTGCGTCCCTC CCAACAGGCTTGTAAAAAATACTTTTTAAAGAGTATTTTTGAGTGCTGGGGCAATAGTTT AGGGGTACAGGTAAAACCCCAATACCTCCAGAAAGGAGTGTGTGGTCAGAAATACCATCT CAGAATAATCGTTTAAACGTCTTCTCTCAATGTTTGTGTCCGTTTCTTTTTTTTTTTTTT AAAGATTTATTTATTTATTATATGTAAGTACACTGTAGCTGTCTTCAGACACTCCAGAAG AGGGTCTCAGGTCTCATTACAGATGGTTGTGAGCCACCATGTGGTTGCTGGGATTTGAAC TCTGGACCTTCGGAAGAACAGTCGGGTGCTCTTACCCACTGAGCCATCTCACCAGCCCCT TGTGTCCGTTTCTTTCTCCATTTATCAGGTTCGAAAGAAGAACTCCCTGAAGGACTGTGT GGCAGTGGCTGGCCCCCTGGGGGTCACACACTTCCTTATTTTGACCAAAACAGATAACAG TGTATACTTGGTGAGTGCGCGCCACACCGTCCCTTTCCCTCCCTGAGCCCCAGCTGCTCC TGTCTGATGATGAGCCCATTGCCCTGAGCTCTTGTGATGCTGGCTTCAAAGTAAACGCTC TGAAGTGAAGGAGCAGGGCTTTCCCTTCTCTCGCCCCACCCGCCAGCCAGACCCCTGCAC CCTCACCCACCCTTTCTTTGGCAGAAGCTGATGCGGCTCCCAGGAGGCCCCACTTTGACG TTCCAGATCAGCAAGGTGAGAAGGGTAGATATGAGAGCCCGGCTTGCCTGGGGAGGGCCC TGGTCACACGGGTGCTTAGCCTCTCTTCTCCCTCCTTTCAGTATACACTGATACGGGACG TGGTCTCTTCCCTGCGCCGACACCGGATGCACGAGCAGCAGTTTAACCACCCTCCCCTCC TGGTGCTCAACAGCTTCGGCCCCCAGGGCATGCACATCAAGCTCATGGCCACCATGTTCC AGAACCTGTTCCCGTCCATCAACGTGCACACGGTGGGCCAGATCTGTGACAGCTGCCGGG GCCAGGGTTGGACAGTTGGAGGGGGAGCAGACCACATGTTACGCCTCCATTGAGTGGAGA GACTCGCTTGGCATAAAGCAACTGATTTGATGTTAAATTCGGAGGCGGGGCTAGGAGTTG ATAGGAGGGTCTCATATATCTCAAGCTGGCCTCCAACTTTGAGGCTGATGCTGGACTTGA ACTTCTGATCTTCCATCTCTTCTGTGCTTAGTACACCTTGAAAGGTGTTGGGCTTTGTGC ATTGTAGGCCGGCACTCTGCCAACTAAGCCATTTCTCTGCCCCTTATTCTGGATTCAAGG TCGTATGTTAGACCAGGCTAGGATTAGACTTGTGGTCTTTTCTAATAAGCCACCTAGGAA GACTAGAGTGTCAAGTACGCTCCTGGCTCCAGAGCTTCAGATGCTAAACCCTGGCATCAG TGCTTCTCAGATTAGGTTCCTTACAATGTCTTAAGTCTGGTGGTTGGCTTTGGTGGCCCC TTTAGCCAGTGCTTCAGACAGTCTGAGGACTCTGGTTGTAGTAGCCCCTAACACCTGCAC TAGGCATCCTAGTGCCTTCTGCAGACACAGACTGCTGGAGAAAGCTACACTCCTTCCCAG CTTGGTCCCTGGTTTCAGCACATAGTTCCCCAGGCAGGCGGCTCACGGTCCCCTTGCCTC TACTCCCAGGTGAACCTGAACACCATTAAGCGCTGCCTCCTCATTAACTACAACCCTGAC TCCCAAGAGCTGGACTTCCGACACTAGTGAGTGTTGGTGAGAGGGAGGGAGGGACTCAGT GTGGGACACCCGTGCACCTGATGAGAATTCTGCTGCTGAGGTTGTGTGATTGCTCAGACT CAAAGTAAACGCCCTGATGCATGTACAGGAGAGGGCAGAGAGCTGACCGTGGACTCCATG ACCATTCACCTCTCCCCCTACTCCCGCCATTGCAGCAGCGTCAAAGTGGTTCCCGTGGGT GCAAGCCGCGGCATGAAGAAGCTCTTACAGGAGAAGTTCCCTAACATGAGCCGACTGCAG GACATCAGTGAGCTGCTGGCCACGTAAGTAAGAAAGCTGGTGGGTGGCAGCTGCACCTGT GGAGCGCCCAAGGTAACCTGTTGTTTTACACAGGGGTGTGGGGCTATCAGACAGTGAGGT GGAGCCAGATGGAGAACACAACACCACAGAACTGCCCCAGGCTGTGGCCGGCCGTGGCAA CATGCAGGCCCAACAGAGCGCCGTCCGACTTACTGAGGTGAGGGTGGCTATGGTGGCCCT CTCAGCTCCCAGTCACAAGGCTAGCCTGACTCTCTTCCCATTCCCCTGTGTTGGCAGATT GGGCCCCGGATGACACTGCAGCTCATTAAGATCCAGGAGGGCGTCGGGAACGGCAATGTC CTCTTCCACAGTTTTGGTGAGGGGACAGGGTGAGGCCAGCCCGTGAGAGCAGTGTCGAGT CCCACTGTGACGTTGACAGATTGTCTGATCCTTCCTCACAGTACACAAGACAGAGGAGGA GCTGCAGGCCATCCTGGCAGCCAAGGAGGAGAAGCTCCGGCTGAAGGCACAGCGTCAGAA CCAACAGGCAGAGAACTTGCAGCGCAAGCAGGAGCTGCGCGAGGCCCACAAGAAGAAGAG CCTGGCAGGCATAAAGCGAGCCCGTGCAAGGGCCGACGGTGACAGTGATGCTGAGGACCC AGGGGCACCGCCAGAGGCAGTGGGGGCAGGTCAGCCTGAAGATGAAGAGGATGACGCTGA GTATTTCCGCCAGGCTGTGGGGGAGGAGCCTGACGAAGGTATGTGGCAGGGTCCTCTGGT GACACCTTGGCCCTTTTCATTTCTTCTCCATTAATCACATTTAACCACTTCTCTCCCTGC AGACTTGTTCCCCACAGCGGCCAAGCGGAGACGGCAGGGGGGCCCTCTGGGCAAGAAGCA GCGAGGGAAGGAGCAGAGGCCTGGTAATAAAGGCCGAGGTCAGGGTGGCAACTGGCAGGC TCTGAAGCTACAAGGTAGATCCCAGAGAGGCAAGGCCAAGCCGAGACCCAGAGCCACACA CCAGGACTCACGCCCAGCATCAAGGAGAAGAAACTGAACCTGCCGGCAGTGGGTGGACTA TGGATGCCCCAGATTGGGGCCCGGAAGCTGCCTGGGATCCAGTGCAGTCCGGTTTCCTTT TATAAAGGAACTGCCCAGTTCTTAACCTCCAATAAACCTGAACATGGTGCTTTTTGAGTC TTCACTCTGGTTGGGGGAGGGCAGAGCTAGCAGTACTTGGATAGTATAAGGAGGAAGTGG GCTAGGTGGGAGGTGTCACACTGACTAGCAGTAGAGATAGGCCAGTGACCAGACTGCTGG GAACTCAGGCCAGGTGGGACCAGAAGCTGCTGTGAGGATTATGTCTGCCCCCTCAGGTAA CCAGGTGCCAGCTCAGGGACATGAAGGGAAGGGTGGTGGGAGGGTGCTAAGGGAGCTTAA GGTGGCCAGGCCAGAAGTAACCACACTGCATGTGGTTCTTACGGCTGCTGGGAGGGGAAC CGTGCAAGACTGCAAATTGGGAGCAGAGTTTGGAATGTTATCTGTAATGGGACCTGATGC ATTCCTCAGAATGAGTGATGTGATGTCTCCACCTGCACCATGCTGTGTCATCGTGTGTGT CCGAAGACAGCTGCAGTGTAATTATTTAATCTTTTTTTAAAGAATTTTTATTTATGTGAG TAAACTAGCTGTACAGATGGTTGTGAGCCTTCATGTAGTTGTTGAGAATTGAGTTTTAGG ACCTCTGCTCACTCCAGCCCAAAGATTCATTATTATACATAAGTACACCGTAGCTGTCTT CTGGCACCCCAGAAGAGGGAGTCAGATCTCAATACAGGTCATGTGGTTGCTGGGATTTGA ACTCAGGACCTTTGGAAGATCAGTCAGTGCTCTTAACCACTGGCCACCTCTCCAGCCCTC CCTCCACCTTCTTAAGGAATTTCATGTGTGTGTAGTGTGCTGTTTATATGTGGAGGTCAA AGGTCAGTGCCAGGCATCTTCCTTAATTGCAGTCAGCGCTCTTACCCACTGAGCCATCAT CTCACCAGCCCCCTACATAATAAATCTTAAAAACAATATTTGGGAGCTGCTGGCAAGTAC TTAAGTTTCCAGGACTTCCTCTGGCTCATCCTGATGGCAGGGCTCCACAGTAGCAACAGT CTCTTCCTGTGCCATTTCTTTCCCCCGGC
Untranslated Region
Coding Sequence snoRNA |
|
| exon position | 1001..1047, 1137..1307, 2068..2169, 2364..2414, 2501..2671, 3369..3445, 3635..3742, 3813..3936, 4017..4095, 4181..4477, 4562..4908 | |
| CDS position | 1030..1047, 1137..1307, 2068..2169, 2364..2414, 2501..2671, 3369..3445, 3635..3742, 3813..3936, 4017..4095, 4181..4477, 4562..4773 | |
| accession no | NM_145610.1 | |