

|
|
|
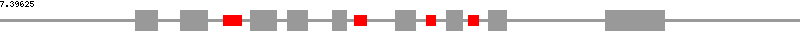
| Macaca_mulatta NOL5A | ||
| organism | Macaca_mulatta | |
| locus name | NOL5A | |
| chromosome ⁄ contig | 10 | |
| snoRNA list | SNORA51, SNORD86, SNORD56, SNORD57 | |
| snoRNA position | 1654..1785, 2623..2708, 3152..3222, 3467..3539 | |
| length | 5918 | |
| sequence |
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNCCCCTGA GTGCAGTCACTGATGTCTCCATGTCTCTGAGCAATGCCTGATGGGGAGGGGTCTAGGTAT GCCATCCCAGCATGCTCCGTGGAAGCAGGGTAATCAGCTGAGGAGATGTTAGAATTGATC ATCCTTCAGCCTGTGAGTGGGAACTGTGTTCTTTCCTCTGAGGGGTTGTTCATGAGGACC TCCGCCTGCTCTTGGAGACCCACCTGCCATCCAAAAAGAAGAAAGTACTCTTGGGAGTTG GGGATCCCAAGATTGGTGCTGCAATACAGGAGGAGTTAGGGTACAACTGCCAGACTGGAG GCGTCATAGCTGAGATCCTGCGAGGTGAGACCATCATCTGTTATATTCATGTTATCCTTG ACATTTTCGGGGAGGAGGTTCTGGAAACGTGGGTGCTTGTTGTGACTTCTGGGAAGGCCT TGGACTTGGCTGGTGCCCATGGGTGCGGGAGCTAGCTCAGAGCCCCTTGTTGCTCACCGT CCTGCCCTCTTCTTAGGAGTTCGTCTGCACTTCCACAATCTGGTGAAGGGTCTGACTGAT CTGTCAGCTTGTAAAGCACAGCTGGGGCTGGGACACAGCTATTCCCGTGCCAAAGTTAAG TTTAATGTGAACCGAGTGGACAATATGATCATCCAGTCCATTAGCCTCCTGGACCAGCTG GATAAGGACATCAATACCTTCTCTATGCGTGTCAGGTAAAGTGCAGGGGCCACCCATAAT ACTGGAGCCTTTGGTCTGTAGTTTAGCTAATTTTGAGTCTTGATGAGGACTGACCATCCT GTGGGTAGAACTATGTGGACTGGGGCTGGGTCTAGGCCTCCTGGTGCTTACCACAGGCTG TGTTCTTACACTGACTGTATAGAAAGAGGAGGTAGAGTAAACCTACCCTATATACACCTC AGCTCAGGCCCTGTGCCTGGTCTGTATTGTGAATGGGGGAACATAGAATGAAGATTTGTA GCTCTATGGTTTTTGATGAAGCAGCTGGGCCAGGGAGTGACTGTGGCTCTTTGCAGGGAG TGGTATGGGTATCACTTTCCGGAGCTGGTGAAGATCATCAACGACAATGCCACATACTGC CGTCTTGCCCAGTTTATTGGAAACCGAAGGGAACTGAATGAGGAAAAGCTGGAGAAGCTG GAGGAGCTGACAATGGATGGGGCCAAGGCTAAGGCTATTCTGGATGCCTCACGGTCCTCC ATGGGTCAGTGCAGAGCCTGGCAGCCTGCATAAGGTATGGGGCTCTGAGTATCTGGCCTC CTGCATTCACACTTGGTTTTTCCTAGGCATGGACATATCTGCCATTGACTTGATAAACAT CGAGAGCTTCTCCAGTCGTGTGGTGTCTTTATCTGAGTACCGCCAGAGCCTACACACTTA CCTGCGCTCCAAGATGAGCCAAGTAGCCCCCAGCCTGTCAGCCCTAATTGGGGAAGCGGT GCGTCATGGGACACAAAAATGGGAGAATAAGGACTGTTGCCATGTGCACCTGCACTGCTG TATTTCTTCACCCACTATGTCTTCCCTAGTTGTGCTTGATGGGGAGGTGGGGAGCAGGGC TGTCATGCAACTGGCAGGTTAGCAGTTCGTTTCTCTGACTGCTTCCTTGACTCTTTCCAG GTAGGTGCACGTCTCATCGCACATGCTGGCAGCCTCACCAACCTGGCCAAGTATCCAGCA TCCACAGTGCAGATCCTTGGGGCTGAAAAGGCCCTGTTCAGGTACCAGTGAGGGCACCTG CCCACAATCAGGTGCCACTTCTGGTGCCCACTGCTTGTTGGGGGATCACGGTGATGGCTG ACCAGGGCTCCCTGACCTATACAGGCCTCTGCTATGGGGGTGATGGCCAGTCCTGGTGTC TGAGTGATTCCCAGGGCCCAGCAAAGGGACCAAGTCTCCAGGTCAGCGACATCGGATGCC TTCCCTCTGCCTCTGGGAGCTATGGGTTGGCATGCATTGGGGTAGAGATCCAATCTGGCC TGAGGCTCACTCAGGACTTGGGGGTGAGAGGAGGGGAGGAGCTGAGCTGCCTTGGCTAAT GGGGTTGAAATTTCTGATCTTAAACTCTCCACTGAATATTCTCTCAGAGCCCTGAAGACA AGGGGTAACACACCAAAATATGGACTCATTTTCCACTCCACCTTCATTGGCCGAGCAGCT GCCAAGAACAAAGGCCGCATCTCCCGATACCTGGCAAACAAATGCAGTATTGCCTCACGA ATCGATTGCTTCTCTGGTATGGGTGGGGGGGCTGGCAGTTGTGAGAAGGGGCTGGCTAGC TGGGTGGGTGGGGAGGCTCACAACCATAGCTTCCACGATGATGGCAATATTTTTCGTCAA CAGCAGTTCACCTAGTGAGTGTTGAGACTCTGGGTCTGAGTGAAGCTGAGGGCAGAGGGA ACACAGGGTGGGGGTAGTTTTTCTCTTTGGGCTGACAGGCTTTGTTACTCACGCACATCC AGAGGTGCCCACGAGTGTATTTGGGGAGAAGCTTCGAGAACAAGTTGAAGAGCGACTGTC CTTCTATGAGACTGGAGAGATACCACGAAAGAATCTGGATGTCATGAAGGAAGCAATGGT TCAGGTTAGTTGGGCTTTGCTGGGTGTGGAGAGGCATAGCTAGCTGTTGGAGGTGATGAA CTGTCTGAGCCTGACCTCGTAGAGTGGAGGCAAAAAAAACTGATTTAATGAGCCTGATCC AATAATGCCAGAAAGGAGTCCTCAGAGCACCAAAGGCCTTCAGGCCCTTTTAGCACTTTT CTTTGACCAGGCGGAGGAAGCGGCTGCTGAGATTACTAGGAAGCTGGAGAAACAGGAGAA GAAACGCTTAAAGAAGGAAAAGAAACGGCTGGCTGCACTTGCCCTCGCATCTTCAGAAAA CAGCAGTAGTACTCCAGAGGAGTGTGAGGTCAGTAGGCAGCATGACCCTGGCAGAGATCC TAGGTTGTAGGATTTTCAACAGCAGAATAAAGGATGTGCTGCATCAAGTCATGGTCTTGA GTCCAGGCTTTTGGACTGAAACAAGGACCTGAAACATCTAAAACTACCTCTTGATTCTAT AGGAAGGATATAGGTGCTGAACTTGCTCAAGAGCCCAGAGAGCTGGTTGTAGCTCACACC TGTTCCCTGGGCATGTGTGTTCTGTCCTCGGCTGCTTCCCAGGAGTCCTCAACCTGGGGT AGTGTAAATTCCTGCTCTGCTTATTCTCAGACGTGTGTCCGGAGGTGGTAGTGTTTCACA GTGGGGATGGGGGCAGGGAGGTCCCCAATGTGCTAAACTGCAATCATTCTCCCTGAGATT TTCATTTAGCACCCAGTTTCTTAAACAGTGTTTCAGGGCCCTGTCTGGAACTTGGCATGA GGGTTCTGTTGTGACCAGCATGGTGGGTGTTTCTTTAGGTTTTTTTTTAATGGGCTGAGG TAATTTCTTATTACATGTTTTCCTTCTAATTTGGGACAGTCTTTGGGATGGATCTCTAAA GTTAATACCCACACAATTAAACTATGCCAGAAACACTGGGCAATGTCAGTAACTACACAG TTTTCCCTGCTTTGGCTACTTAATTGCTGAAGATGTAATGGGGGTGTGTGTGATGGCACT GTTCTCACAGCCTGTTCCCCTGTCCTTCCCTTTAGGAGACGAGTGAAAAACCCAAAAAGA AGAAAAAGCAAAAGCCCCAGGAGGTTCCTCAGGAGAATGGAATGGAAGACCCATCTATCC CTTTCTCCAAACCCAAGAAAAAGAAATCTTTTTCCAAGGAGGAGTTGATGAGTAGTGATC TTGAAGAGACCGCTGGCAGCACCAGTCTTCCCAAGAGGAAGAAGTCTTCACCCAAGGAGG AAACAGTTAATGACCCCGAAGAGGCAGGCCACAGAAGTGGCTCCAAGAAAAAGAGGAAAT TTTCCAAAGAGGAGCCAGTCAGCAGTGGGCCTGAAGAGGCAGCTGGCAAGAGCAGCTCCA AGAAGAAGAAAAAGTTCCATAAAGCATCCCAGGAAGATTAGAATGCAAATGGACATTCTC TGGGAGGTGGGACATACCATAGCCCAAGGTGACATCTTCCACCCTGTGCCCTGTTCCCCA ATAAAAACAAATTCACAAAAGTTGGTTCATGTTCTTTATTGGACACCTTACATGAGTATG GACAAGGCCTATGGGTGGGGCAAGGCAGCAATGACAGCCTCAGTGAAGTCATGGCAAGTA GCATAGCCACCCATGTCAGAGGTTCGAACCTGTGGGGGAGAATCATCATCATCCATGTGG CCTGGGTTCCAGCCTAACAATTCCCATCACCACCCAACAGTCTCCCCTAAGGAAGCGGGC CAGGACAACCTAGGCTCTACCCAGCAAGGTGACCATGGTCCACTGCCTAGAGGCACAAGG TCTCTTCCCTGGTGCACTGCACTGAAGGGTATGGGGAGTGTGGTCCTTGCAAGGCTGGAA GAAATAAAGGGCTCTAGCTCCCATGGGGGTGCAGGTGACCGATGACAGACTTGATGAAGT CGGTTGTGGTGCTGTAGCCGCCCATGTCTCGAGTCCGCACCTACAGCCACCACCGGCAAC AGCCGTGGGGAGGGAGAAAAGAGAGCCCATGAAGGGAGATAGGGCAATGTGATTGAGGAA ATGGAATCCAAGAATGCGTGACAGCCAGAAAAAAGAGGCAATGCACAGGAATGGAAGGAG GAGCCAGGTTGGGAAGCACATGGACCTGCCCACTCCTCTTAAGCCACTATTAGCTGTGCT GCAGCCAGAGCAGGACAGGAGGCTGAGCAGGCAAAGATGATGGGAAATGCAGATCAGAGG CGCAATGTGGCTACCTTCCTTGGAAGAAATAGAGACAAGACCAGGTGGAAGGAAAGAATC GCAGCGGAAAGGAGATGGGTGTGAAGGTGAAGCTGATGCTTCAGCCTGCCTGTATCCCTT GCTGTTCCACCCCCAAGGAGAGCTGCAAGTTCTGCATTCAGATGGCCCATGAAAAGGGCA GTGGATGGAGCAGGAAAGAGGGAACAGCAGATGGGATCTAAGAGGCAAAAGAGATCAAGA GGATGAAACAGCCAAGAGAAGGGAGGTGAAGAACAGCCC
Untranslated Region
Coding Sequence snoRNA |
|
| exon position | 1001..1163, 1336..1534, 1856..2043, 2126..2277, 2460..2560, 2927..3075, 3302..3423, 3610..3747, 4475..4918 | |
| CDS position | 1001..1163, 1336..1534, 1856..2043, 2126..2277, 2460..2560, 2927..3075, 3302..3423, 3610..3747, 4475..4837 | |
| accession no | ||