

|
|
|
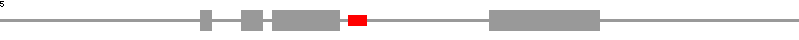
| Caenorhabditis_elegans uaf-2 | ||
| organism | Caenorhabditis_elegans | |
| locus name | uaf-2 | |
| chromosome ⁄ contig | IV | |
| snoRNA list | Y116A8C.50 | |
| snoRNA position | 1741..1834 | |
| length | 3998 | |
| sequence |
TGTCCTCCGGTTAATTGGCCGAACATTGCGAAATTCTTCTGATATTCGGCATCGGAAAC
TTCCCAAGGATTTGTCATCTGGAGAACAGGGGATTTTTCGACAAAAAATGGGAATTTCGC AACAAAAAAGGGAAAAAACGAGCCATATTTTTCTAATTTAACTGGAAATTTATGCGAAGA ATCAGCGAAAATGATGAAAAAACACATGTTTTTGGGCAAACAATAGATTTTTTTGAGCCG CTCCGCTCGCCAGCTGCGTCGCGGTCGTGGCCGTGGCCTAGGTTCCCTCTCGGCCATTTC TGTAAAAATTGGCCGCGGCGCGGCGCGGCCGGCGAGCGAGGCGGCTCAATAAAATGTAAT TTTTTGGCTAAAATTCGTGATTTTTCCCTAATTTAGCTGGAAATTTCTATGTAAACTTCC CACGGATTTGTCAATTGGGGGTTTTTCGATTAAAAACGCTAAAAATGCGAATTTCGCAAC AAAAAGAGAAAATGCGCCGAAATTTCTGTAAATTTGGATTCAGGAACTGAGAAATAAGAA GAAATAAGAAAGAGGCCAAGCGCCGCCGAAAGCTTATCGATTTTTGCGTGCCCCAAAAGA GGAGTGGTCCCCGAGAGCGCGCGGCGAGAGATGCAAGAGACGCAGAGAATTTTAAAGGAA TCAAAAACCCCTTTTTTATATATTTAAAAAAATCAATGTTTTTTTTTTCATTTAAAACTT TGCATTTTAAGAACAAATTTTAGTTTTAGAGTGAAAAATCTCGTATTCTTGAGTTTTCTC CAAATAATTTTGAGCTCCAATTGATTTTTAAATGTTCTTTCAGCCTTGGTGCATGAATTA ATCGGTATAATCGCGGAAAATTGAAGAGAAATTCACTTAAATTTCAACTTATTTATTAAT CTCTGGTCATGGGAGAAAAAAAGAAAAATAGAGAAAACGCTAGAAAAACGCGCGCGCTCA CCTTGCCGACGCTCGCCCCGCCCACAAAAGCGTGCCTCGTTGCGTTTTCGAATTTAGCAG GGCAGTTGGTTATTATTTCCATTTTCTATCTGTTTCAGGTTCGCAGTTTGTTTTTTGCAT TGAATTCTTGATATTTTGAGTTTTACGTTGTATTCTGAAGTATTTCCGTCAGAATTTGTG TTTAAAAATCGTAATTCTCAGGGTTTTCCCGCTGAAATTGAATTTTTCGTCAAAAATCAT TTTTTTTAGTGAATCCCAATGTCGTATGGTGACGGGCTCTCCGGAGCCGAGTACCTGGCC TCAATCTATGGTACTGAGAAGGATAAAGTCAATTGCTCGTTTTTCTTCAAGGTTTGTTGT GGATTTCTGTGAAAAAATTCAATAATTAAATAATTTTTGCAGACAGGAGCCTGCCGCCAC GGAGACAAATGCTCCAGAGCCCATCATACACCGACATTCTCGCCAACAGTTGTGCTCAAA AACTTCTACCACAATCCGGTAGTGGATGTCCGTCAGGCGGATGCTTTCGATAAAGTCGGC AAGCGGAATGATCAGGAACAGCGCTATTTTGACGATTTCTACGAGGAGGTTTTTGTGGAG ATGGAGCGAAAATATGGAGAAGTGGAGGAGATCAACGTTTGTGAGAATATCGGAGAACAC ATGGTCGGAAACGTATACGTCAAATTTATGAAGGAAGAGGACGCCGAGAAAGCAAAGAAT GATTTGAATAATCGATGGTGCGTAAGCTGAAGCTGCTGTGTTGATAGGGCTCAAGCTGAG CTCAAGTGCTGTGAAGAGAACGTGCCACTGTACTTTGCCCATCGGAAGGGCATTGAAATG GAGATATACCTGGCACAGGGGCCATCTGAGCACTTTGGCGAGCTAGCCCGTATCATTTTT GCTAATTTAGCTGGAAATTTGTGCAAGAAATCTGCGAAAATGATGAGAAATCACAAATTC TGAGCCGCTCCCGTCGGCCATTTCGTTAAAATGGACCGCGACGCAGCTGGCGAGCGGGGC GGCTCAAAACATTTAATTTTTTGACCAGAAATCGTGATTTTCCATCTTTTTTCATGTCAA CTGCAAAAATGATGGAAAAATCACTAAATCTGGGGCAAAATATAAATTTTTTTGAGCCGC TCCGCATGCCAGTTGCGTCGCGGTCATGGCCGAGGTTCCCTCTCGGCCACCTCTGTAAAA TGGACCGCGACGCAGATGGTGAGCGGAGCGGCTCAAAATTTTTATTTTTTGCCCAGAAAT CTTGATTTTCCATGTTTTTTTGCTAAATTAGCTGGAAATTTGCACCAAGAATCAGCGAAA ATGATGAAAAAACACAAATTCTGGGGCAAAAAAGTATATTTTTTGTCCAGAAATCGTGAT TTTTCCGTCTTTTTCCTGATTTAGCTGGAAATTTTTATGCTAAATGCAAAAATTATGAAA ATTTTCTGTAAAATTATCGATTTTTAAAATATTTTTCGCTTTCAGGTTCAACGGACAACC AATCTACGCAGAGTTGTGCCCTGTCACCGACTTCCGCGAGTCTAGATGCCGTCAACACGA AGTTACAACCTGCTCGAAAGGAGGATTCTGCAATTTCATGCACTTGAAGGCAATTTCCGC CGAACTTGGAGATCGTCTGTATGGTAGACGTGGACGACGAGCCGACGCAGCTGGACATTA TCCATCACAACGTGGAGGTTCCGGAGGCGGCGGTGGAGGTGGTGGCGGCGGTGGCTATGG AAGCGGTGGAGGATGGGGTGGCGGCGGTGGCGGCAGAGATCGTGATCGTGGAGGATGGGG TGGAGGCGGCGGAGGTCGTGGATATGGAGGTGGCGGTGGCGGTGGAGGCTACGGATATGG AGGTGGAGGCGGTGGAAGACGCCGCAGTCGAAGCCGTGATCGAAGACGATATTAATCTCT CTTGTTCTTTTTTTTTTACCTTTTTTCTTCTGTATCTTATCTCATATAATTCCAATAATT CTGCTCTTTTTTCTCTATCTCTCTCTTTTTTATTGCAAAAAAAACCATTTTTATTTCCTT CTTTTTGTAGTTTTTTCGCCAAAAAATGGTTCTGTTCAGCCATCTTTTTTACCTATTCAT TTAATTTTCTACAAATCCACCTGCAAACTGCTCAGAAATCCCAGATGAACACGAATTTTC CACACAATCGGAAAAGAACGCTCTACGTCGGAGGTTTCACCGAGGATGTCACTGAAAAAG TGTTGATGGCCGCGTTCATTCCGTTTGGAGACGTCGTTGCCATCTCGATTCCGATGGATT ACGAGTCGGGAAAGCATCGTGGCTTCGGATTCGTCGAATTCGATATGGCTGAGGATGCGG CGATGGCGATTGATAATATGAACGAGAGCGAGCTGTTCGGAAAGACTATTCGGTTAGGGA TTGGCTCTGGAAACCAAGAAAATAGTCCTAAATAAAGTGGAATTCTTGCGTAGTCTACTA CGTAAAGTGAAACTCCAGCGCAAATCGCAGTTTTTCGTAGTTTGACACCAGGAAATTTAA ATTAATTTTCAATTTTAAACGTAGCAACGATGCTCCGAAATAACGCACGCGCATGTTATT TCGGAGCATCTTTTAAAATTAAGATTTAATTTTAATTTTGTTTTCAAAATTTTCCTAGTT TTCAGGTTTAATCTTTGTGATTTTTCATATTTTTTTAAAGATATTTTTACAAGTTTTTCA ATAAAACCTGTGAAAAAAACATTTTTTATAATTTTAAAATTGCTATTTTCAGTGTCAACT TTGCTCGTCCACCAAAAGCCACCGAACGCTCACAGAAACCTGTCTGGGCAGACGACGAAT GGCTCAAAAAGTATGGAAGAGGTGGAGAAGCTGCTGCGGAAGAAGACGGAGACGCTGAAA AAGCCGCCACGTCATCGTCGTCAGCCTCGACGAAGCTTCCACGTGTCTATCTGGGAGTGA AGATTGGAATTCGATATATTGGACGAATAGTGATCGAGTTAAGAACTGACGTTACACCGA AAACTGCCGAAAACTTCAGATGTTTGTGCACAGGAGAAC
Untranslated Region
Coding Sequence snoRNA |
|
| exon position | 1001..1057, 1209..1310, 1362..1696, 2445..2998 | |
| CDS position | 1218..1310, 1362..1696, 2445..2871 | |
| accession no | ||