

|
|
|
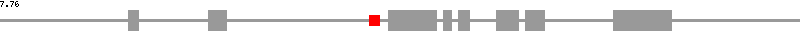
| Caenorhabditis_elegans T06D8.3 | ||
| organism | Caenorhabditis_elegans | |
| locus name | T06D8.3 | |
| chromosome ⁄ contig | II | |
| snoRNA list | T06D8.11 | |
| snoRNA position | 2871..2947 | |
| length | 6209 | |
| sequence |
AGAGCCGAGGTTGGTCTAGGACTATTTACTACAGTATTATGTTGAGTTTCACCCTGCTA
TTTTGCTAAAATGATATCAAAGTGAAACTTTTCAACTTTTTTTTAACTAAAAAAGGGTAG ATACCCCAATGTTTGCCTTTTTGGAGGTCGACCAAAATAAGGTTTTTTTTACAAATTATA TATTTTAATTATGTTTTTAAAATTTGTATTTGAACAATGTAGGGATTTAAACAACTCTAA ATTTCTTTAAAAATTCCAGCCTTATCGTAAATTTTGCAAGTTGCGAGAATTTTGACATAG TACTTTTGGACCGTTCCAAGTGTATTTATTAATTCCAGACTAGATGAGATTTTATTACAG TTTATGCTAAACTAAAATAAATTATAGCAACTTTAGGTTGAACTCTAAATTTCACAACTC ATATAAGTCGTCTTTTAAGCCATTTTGTAGAATTACAGAAAATAATTTTTCTCGGCATTT TATTATCACGTTCTAGTTCATTCCATTTGTAACACAAAAGAAACTCTACGAAAAAAATGC ATAAGTCATTTGTAAATCGGAGGCAGCGCCAGCTTCTTCTCTACTTGACTTGTTTACCCA TCACGTACGGTACGCAGCCTGAAGCGCGGAGCCCAACGGAGACGCAGACTGGCTAGTTAT ACCGTCCGCCTACCTGTCTCCGACCGTCGGGGGCGAGCTCACCGGAGAGAAGAGCATCCG CGAGCACCAGCACACACACACCCCTCTCCCCCTAAGAACAGTTAAGCATCGATCGATCGG ATGCTCATGATTCTCAGGAAGGGACACACCTTGGGACAACATCACTTTTTTCAATTTTTT GAAATCTGACTCATCACCTGGGAGTATTTTTTTGCCCATCCTATCTTGTCATACATCCTG TCAATATATTATAAATCAACTCTTACTTTCTCCATTTTTTTCGAATTTTGTTTTCGACGA TTATTTGTTGATATTATTTTTTCTTACGTTCCAGAAATCTGAAAAACGACAAAATTACGA AAATTCCGGGGCGCAACGACATGTCCGTGCCAGCTTCGCGGGCACACTCTGAGGTAAGAA ATGTTTCGATTTTTACTTAAAAAATACTGTACCCGGTCTCGAAGCGACAGATTTCTTTAC ATTTCAATTCAAAATAACGTGTGCCTTCAAAGTGGACTACTGTAGTTGCTAACTCTTTGT TGTTGCAAATTCGCAAAGTTTAATTTTTTTTCCTATTCATTCCTCAACGATTCTTCAAAA CGTAATTTTCAAAATTAAAAAAAAACAAAGAAAGTTCCGCAACATCAACAGAAATTAGAA ACTACAGTACTCTTTAATGTATGATGAAAAAATCGGTCGCTGCGAGACCTGGTACCGTAT ATTTTGTGCCAAAGTGACAAAATTTAATGTCTGGTTTATAAAAGTTTACAAAAACTTCCC AGTTATCAAAATTTGGGGTACTCGGGCTTTCAGATTACCACATATTTTGAGATGAGTGAT TCTGAAAGCCGTATGCCTCAAAACTTTATTATGCTTCCGTAAATTATGACTTTTTTTTAA ATTGTAGCAAATTTGATGCTCAAACTCTACACTTCCCTCAACAACATCCCCTTTCAGGTG TTCTCGGCGAGCCAATACGGAGGTGTGACCACAGTTCCCGCACCACGACCCCGCTCCTAC ATCAACTATTTCATTTTTCCATCCGCAGTCCTTCACGTCGTCGGAATTGCGTGTCTCGCC GCACTTTGGTACTACTTGAGGTAAGCCTTTGACAGTTCCTTATTATTACTATTATTTTCG TTGTGATTGACAGATTAGGTACGGCAAATATATGTAGGTTAAGGACAGGAGAGAGAGTGA GAGAAGTTATTGTTTGTACTATGATTTGCTCGGCGAGCTATCGAAATTACTCAAGCTCGG TTGACCTTTTGGTGATTAGAAATAGTGTAATAGGATTTATAGAAACTTTATTATTAACAT CATATGAACATATCTGTGAAATTTTGCACCTTCAGCGATCCTTATGACCTAGATTGTGGC GAGATCCATTCCAATAAACATCGTGTGCCTTCAAACTTTTCTCACGAAACTACAATAATC AATTAAAACTTTACTATTTTTGCAAAGCTCCCGGCTAATTTTAAACAATGTAAAACAAGA AGTGTTGCGAAAATAAGGTGGGGGTCAGTCGTGGAAAAAGCTGTGCAAATATACTTTGAC CCATTTTGGAAGCTTTTCGCATTGTCTCATCTCTTCACCTTTAATTGTGTGTTGCCGAAA ATAGACGAGAAAAAATATTTAAAGAAAGAAATATATTATGTTTTATTATCTTATTTCATA GTTTTCGCGATTTTAGGCCATAAAATACGGTCCCTGGTCTTAATGCGACATTTTTTGTTT AATAGAAACGGGTGTGCGCCTTTAAGGATTACTGTATTTTATAACTTTCATTGTAGTGGA ATTTTCATCGATTCTTAATAGTTTTTCTGACGATTTTTGAAAACTTATAAGGTTTTAAAC GTTTTACTTTAGTTTTTCCAATTAATAAATATTATTCTAACGAAAAACTATTCAAAATCG ATGGAAACTCCGCAAGCTTGAAGCCACAGTACTCTTTAAAGGCGCACACTTTTTTATTTT AATTTAAAAAAAATTGTCGTGTCGAGTCCATTCACCATAGGTTTGGAAAATTAGCTTAAA ACTATCACAAATATCAAAATCCCCCTCAAAACTGAGCTCAGAACTCCAAAAAGTTGCATC CCCTTCTTCTAGTGGGCGGAGTCCTGTCCCACAGATACCACTGCGATAGGCGAAACTCGC AAGGTGTCCGCCGCGCCGTCTAGTGTACCCAACAAGTGTGCCTCTTATTTAAAGCCGATG ATTACCAAAAATAACCAAATGTTTGAGTGATTGTTTGTGATCGAATTTTGTCACTATCGC TGAGGCTTACAAATTTTGCGAAGAAAATCAATTTTGGAATAATTCCTCTGAAGGATTCAT GTAATATTTTCAGGTTCACCAGTGTCTTCCCTTACCATCATCGGGTATTTTACTGTCGAG ATGTTCACCTCTACAAACCAAACTTTGTACCAGAAGATTTCAACGTCTACGTTTCATATC CTCTACTCTACACACTTGCCTTCACAATTCCTCCCCTAGTTATTCTGATCGGTGAGGTGA TGTTCTGGTTGTTCAGCACAAAACCTAGGAAGATTGTCTACGCGAATTGTGGAGAGTGCC CAGTTCACTTGTTCACCAGAAGACTCTTCCGTTTCGTCATCATCTATCTTGCTGGTCTCC TGATTGTTCAGATTTTTGTTGACACGATTAAGCTGATGACTGGATACCAAAGACCGTACT TTTTGTCCCTTTGCAATGTTTCTATAACGTAAGACCTTTAGAGCATAGTTTATTGTGAAA CCTAGTATAATTATATAATTTCAGCGCCTGTACTGCTCCACTAGAGCATTCACCATCTCC ATCCCCTCATTTGGCCTGCAATTACAGGTTTGTGATAAAGGAGAAGTTATGTCAAAATTA TTTTTGTAATTTTCAGAGGAGCTGATGAGCTTCGTTACGCATGGCTCACGTTCCCATCCC TTCATGCCGTCGTCTCATCGTACGCCGCTTGCTTTGCATCTGTAACTTGCAAATTTTTAG TTTTCAAAATTTAAAATATATGGGAAAAGTTTGATCAAAATGCCATGCTCGGCGTTTTCA TTTCTGCTTCAACACTAAACAAAAAAATATTTCAAATATGTTAAAGGTTGTCTAAATAGA GCCCGGGTACCCCCAAAGAATCAAAAATTCGATCATTGAAATTTAAATTTTCAAAATTTA ATTCTCTCCAGCTCTACATCTACTACATGATTAACTTGCGTGGAGCCCCACTTCTCCGCC CACTCCTTATCTTCGGATTCATGGGACTCTGCATCGTCGACTCGTTCTCCCGTATCAACG GATACAAAAACCATTGGCGTGACATCTGGGTCGCATGGGTCATCGGAATCTTCATGGCTT GGTTCTTGGTGAGTACCTTTAGTAGGCTAGAAATGCAATATAATCTATGATCCTTGTTCA GTGCTACTGCGTCCTGTGCTTCCAAGAAGTCTACCATATGACTATCGAACGTACGCCGAT TGTTCAAGAGGAGCGCGTCTCGCCGTTCTTCAGTTGGTTTAGACTTCCACGTGTTCAGGC TCCGTCGGTGAAGGAGGAATATGTGTAAGTTATCAGGTTTTTGTTAGAGTATCTAGGGTT TCAAATTATGGGCTCAAATAAGTTGTTGCTTAGCTTTTACTGCGGTTTTATTACCCATAA GATTTTTGGCTTTTGACATAAAAATACAGTATCGGGTCTCGAAACGATCAAGACCTCGCC GATACAGTATCTAGAAGGATTTCGAAATTTCTTTGAATTTTCTACAAAGTCATAGATTTT GCAATAAAAAAGGGAATCAGACAAAAAATGTTAATTGTATTTTTCTGTCCAAGGTCGCAA TATTCCGCAACATGGTAATAAGTAGGCAGGTATAGTGCGCAGGCGCAACTTCAGAACCTG TCTGAACCCCGCCTGCCTATCACCTCTATTCTACGTTGTGGCGCGAATTTACGAGTTTCT AATATTCTTGTAGCTTTAAAATTTGAACTGCAGCGCCAATTTTTGGCGTTCTAGAATGGT CTAGTTCAAATACTTATACTTTTCCATATTTCCAAAAGTTAGGAAACATCCAATAAAATA TGTCCAATCACCTAATTTTAGCGTCTACGAGGAAGACGTGGAGCGGCCGAACGGCACACT GCGAAACCGTCATAACCAAGGAAATCGTCAATACGAGGTGACGACAACAACGGAATCCTT CCATAGAACCATCAGTCCACAACAGCAGCAACAACAGCAGCAGGGACATCAAAATGATGG ATATCGGTACTAGGTGCATACACTATCAAAATCTCATATCTCTAATTTTCTCCAATCCCA GAAACCCAGTTTTTTTCTTAATTCTGTTATGCTCATCAAAAAGAATTTCTCATCTCTTTC TCTCCCGCTCTCACTTAATTATTTTTTAAATTAATATTTAATCTAACTATGATATTTAAA TAAATTTCTCTTGTATGTGTATATACCGTGCTCTTAGCGGAATGCGGCATTTTCTCTATG TCTCTGAATACCCGGCAGTCTTTCGCTTTTTTTGCTTTTACAATTTTTTCGTTTATTTCT TTTTTTTTGCTTTGTTTTGCACCACTCAAACCTTCAACAATAAATTATTCAAATTTCGTA TGTTTTTGTGCCCGTCTTGACAACAGTCTCCATGGAGCTCGTCTGAAGATGGTCGAGATG TGTTTTCGTTATATTAGTCATAAGTCGTATGCAGCTGGAGTACGTTGTCTCGCATATTGG CGGAGTGCCAAATTCCGATAAACAGTATCTTTTGGAGAAACAGTGGGTTTCTGAAAAGTG AGTTTTGAAGAATTCCAGTAGAATTTTGAAAACTATCAACTGAGAACAGATAAGATTAGT TGCAGTTATCAACATTTTTTAAAGTATGTTAAAACTTTGCCGTCACTTTTATAAGTAAAA TTTTGTCTGAAAATGTATGGAGGGTTATTTAGGATATCTTGGTCATGTTGGACTATCTGA AATTTGTGAATTCGTACAAGTTTTGGCAATAAGCAGGACTAGTAGTAGGCAGGCAAAATT AAAAAATATATCAAGTTTCATTCAAAAATTTGAATTTCCGCGTAAAGGCAACTTCTTATG AAATTTTAATTCAGCCACATTCATTCATTTTCGATCATTTTTGTGGCAAAAATCTAAGTG TTAGCGGATCTTTTTGATTTTTCTTGTATTACAGTTTCAAAACCGGAGCTACTTTTTTTT CAAGGTCCTATTTTTCCAACAAAAAAAATTTGCTCCCAAAAACAAAATTTCAAAACACTT CAGAGTTCAAGAATAACCAAACATCTCAACACAAAACATACTAGAATATTCATTTTTCTG ATTTTCAGATCCCTTACCTTCCCAGTGGAAATTGAGCTTCATCTCCGTCAAAAGAGTGAA ATTGAGAAGATAGAAATTGTTGCCCATAACAAGTTCATACCGAAAAAAATCTCGATATAC TCTGGCCGAGACGAGGAAGGATATATTGGGTTTGTCAATTATTAAAGTTAGTAATCTTAG CTTCCACATTTCCAGGGATGTTCAGTTTAA
Untranslated Region
Coding Sequence snoRNA |
|
| exon position | 1001..1072, 1617..1759, 3013..3387, 3444..3506, 3556..3640, 3851..4027, 4081..4223, 4761..5209 | |
| CDS position | 1040..1072, 1617..1759, 3013..3387, 3444..3506, 3556..3640, 3851..4027, 4081..4223, 4761..4929 | |
| accession no | ||